本研究は、視覚言語モデル(Visual-Language Model, VLM) を活用し、屋内環境における物体の自動識別および分類を行う新しい手法を提案する。従来の手法では、各物体を手動でラベリングするコストの高さや、記述の曖昧さが課題となっていた。本システムでは、詳細な点群データ(3D表現)とRGB画像 を組み合わせた大規模データセットを学習し、事前定義されたラベルを必要とせずに自然言語による物体検索 を可能にする。
本手法では、CLIP(Contrastive Language-Image Pretraining) を活用し、テキストと画像の統合学習を行うことで、カテゴリに依存しない柔軟な物体認識を実現する。加えて、スマートフォン搭載のLiDARセンサー により取得された環境データを活用し、WiFiの受信信号強度(RSSI) と統合することで、無線環境情報を利用した物体識別の精度向上を図る。RSSIデータを3D点群データに組み込み、無線信号の空間的分布を考慮することで、視認できないオブジェクトの識別能力を強化する。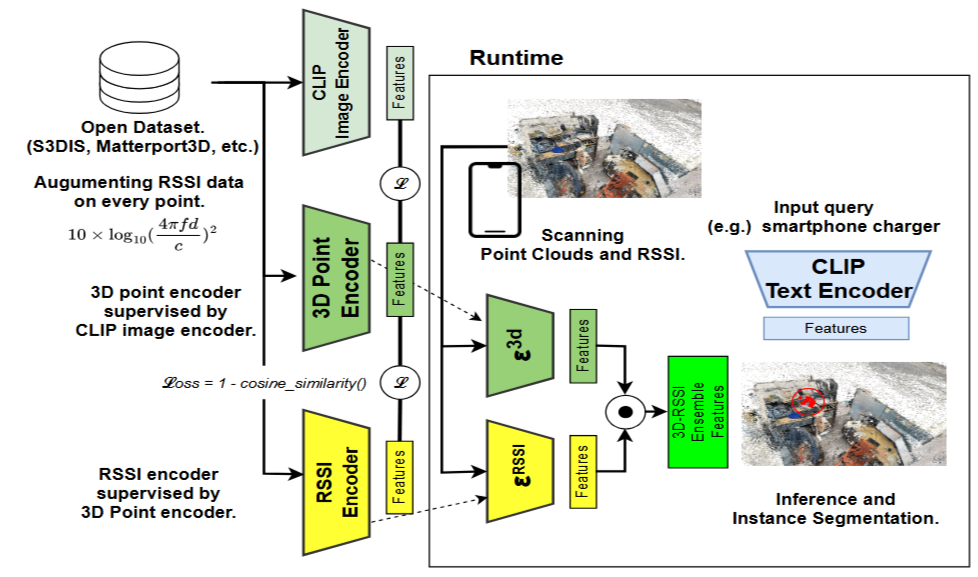

発表論文
- 米倉 晴紀, Hamada Rizk, 山口 弘純, "Mobile Sensor-Based Indoor Object Searching with Visual-Language Model," 研究報告モバイルコンピューティングと新社会システム(MBL),2024-MBL-111,1-5 (2024-05-08), 2188-8817, https://ipsj.ixsq.nii.ac.jp/records/233963
- Yonekura, H., Rizk, H., & Yamaguchi, H. (2024, June). Poster: Translating Vision into Words: Advancing Object Recognition with Visual-Language Models. In Proceedings of the 22nd Annual International Conference on Mobile Systems, Applications and Services (pp. 740-741). https://dl.acm.org/doi/10.1145/3643832.3661407





