本研究では、駅や商業施設などの高密度で動的な環境における自律ロボットナビゲーションの課題に取り組むため、マルチモーダルセンサーデータ(LiDARと視覚センサ)の融合と大規模言語モデル(LLM)を活用した適応型ナビゲーションシステムを提案します。従来のルールベース手法では対応が困難な人間の予測不能な行動や障害物の動的変化に対処するため、FPGAによる高速データ処理とLLMを組み合わせた社会規範に基づく経路計画を実現しました。具体的には、LiDAR点群とTriple-RGBカメラデータをFPGA上でハンガリアンアルゴリズムを用いて統合し、歩行者属性(年齢、車椅子の有無)を考慮したリスク分類と優先度付けをLLMで行います。評価実験では、歩行者位置予測誤差を従来手法比40%削減し、実時間処理を可能とする低遅延性能を確認しています。今後の展開として、Q-LoRAによる推論精度向上やFPGAモジュールの独立検証を予定しています。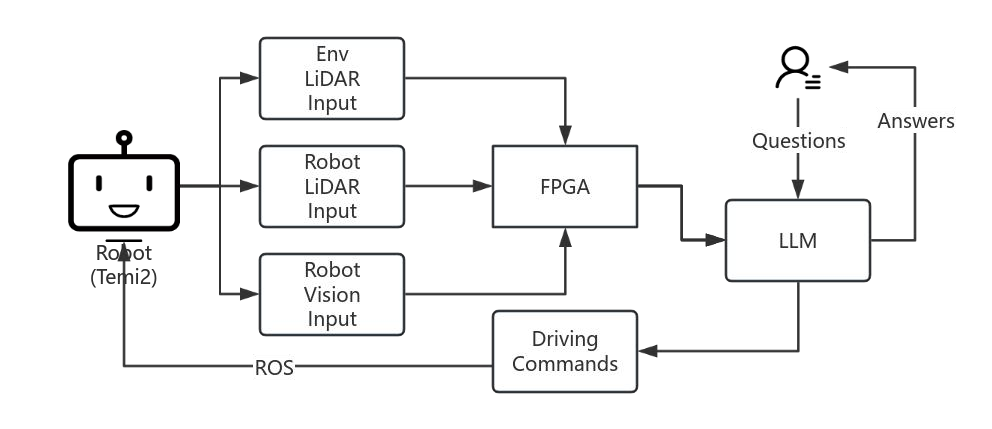

マルチモーダル融合とLLM駆動による動的環境適応型自律ロボットナビゲーション
キーワード
自律走行 マルチモーダル融合 FPGA LLM(大規模言語モデル) 社会規範に基づく経路計画 動的環境適応





