This study proposes a novel method for automatic object recognition and classification in indoor environments using visual-language models (VLMs). Traditional methods face challenges due to the high cost of manually labeling objects and the ambiguity of textual descriptions. Our system learns from a large-scale dataset combining detailed 3D point cloud data and RGB images, enabling natural language-based object retrieval without predefined labels.
Our approach leverages CLIP (Contrastive Language-Image Pretraining) to integrate text and image representations, allowing for flexible, category-independent object recognition. Additionally, the system incorporates LiDAR sensors embedded in smartphones to capture environmental data and integrates WiFi Received Signal Strength Indicator (RSSI) to enhance recognition accuracy by utilizing wireless signal distribution. By embedding RSSI data into the 3D point cloud, the system improves the identification of objects that may not be directly visible.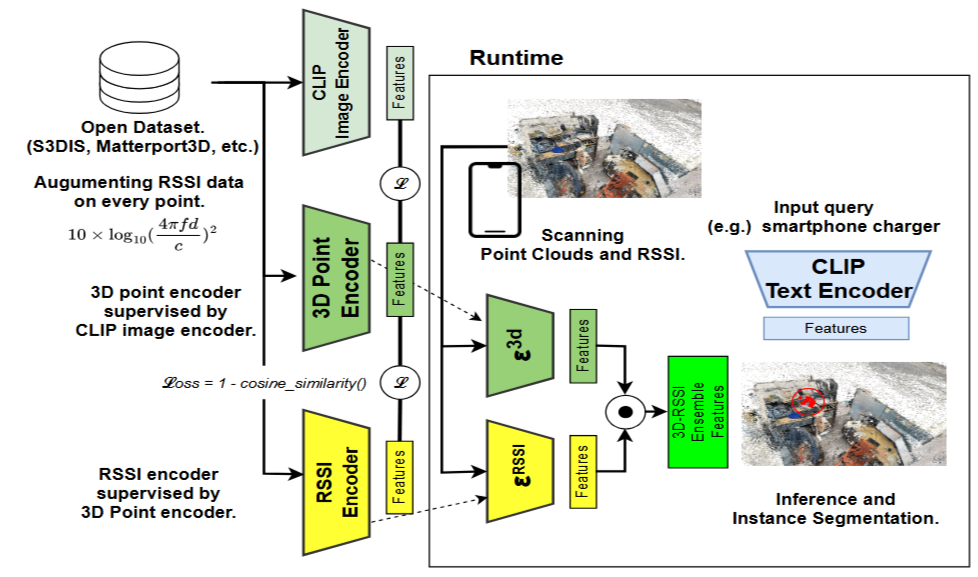

Published Papers
- 米倉 晴紀, Hamada Rizk, 山口 弘純, "Mobile Sensor-Based Indoor Object Searching with Visual-Language Model," 研究報告モバイルコンピューティングと新社会システム(MBL),2024-MBL-111,1-5 (2024-05-08), 2188-8817, https://ipsj.ixsq.nii.ac.jp/records/233963
- Yonekura, H., Rizk, H., & Yamaguchi, H. (2024, June). Poster: Translating Vision into Words: Advancing Object Recognition with Visual-Language Models. In Proceedings of the 22nd Annual International Conference on Mobile Systems, Applications and Services (pp. 740-741). https://dl.acm.org/doi/10.1145/3643832.3661407





